再來是處理 Evaluation
如前面提到,我們現在在做的是中文 ASR 所以這裡要用 CER 來做為評估方式
import evaluate
metric = evaluate.load("cer")
def compute_metrics(pred):
pred_ids = pred.predictions
label_ids = pred.label_ids
# replace -100 with the pad_token_id
label_ids[label_ids == -100] = tokenizer.pad_token_id
# we do not want to group tokens when computing the metrics
pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
label_str = tokenizer.batch_decode(label_ids, skip_special_tokens=True)
cer = 100 * metric.compute(predictions=pred_str, references=label_str)
return {"cer": cer}
Checkpoint 我對他的理解有點像是一個紀錄點的概念,有點像是拿來做一些模型訓練狀況回報
from transformers import WhisperForConditionalGeneration
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small")
後面一樣記得改成自己的模型
model.config.forced_decoder_ids = None
model.config.suppress_tokens = []
這邊其實是在改輸出的語言,我有點忘記前面幾篇有沒有提到這個東西,但那個 forced_decoder_ids 設定過的話,你輸出的語言也會不同
而他其實就是一個數值(代碼),每個語言都有不同的代碼,之前我用 Huggingface 來做轉錄時,他會把中文的音檔用英文來輸出
非常的神奇,一不小心就完成了翻譯了呢!
這邊的參數我懶得貼上來,他原本有幾個變數已經有註解了就不多提
稍微提一下另外幾個變數:
max_steps 總共跑的步數fp16 我後來設成 Falsegeneration_max_length 每次 output 出來的文字最高的長度
save_steps/eval_steps 我設定成一樣,應該是跑幾步就計算模型訓練狀況
訓練時會按照這邊的設定,去決定每多少步要 print 結果出來
push_to_hub 看要不要上傳到 huggingface 給大家開源使用我習慣會先測試一下狀況,第一次用會把步數設成 500 之類的,那樣跑起來的速度比較快,能迅速拿到訓練好的模型
如果結果不優再多增加數目
如果設定成 medium 版的話會發生 CUDA out of memory :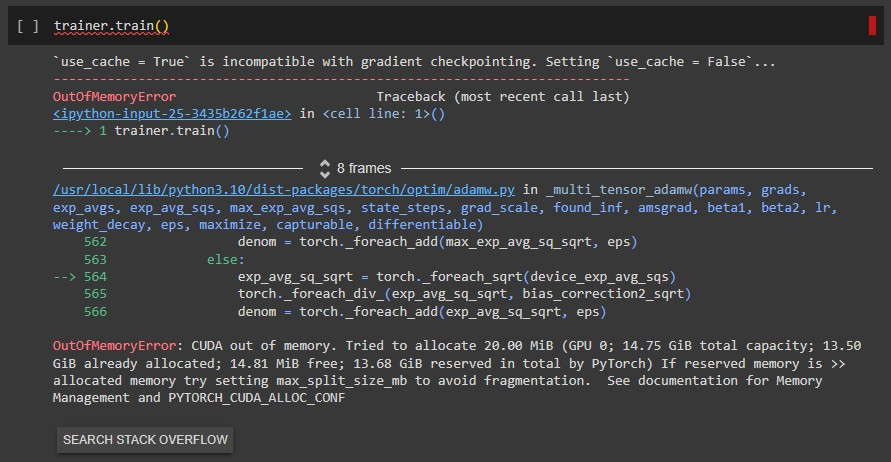
看到這個真的很不爽,要再把前面的重跑一遍
聽說快完賽了,我也好累,這幾天腳站的好痠

